






Dirigindo de bunda quente
18 de Janeiro de 2025, 19:20 - sem comentários ainda

Quem me acompanha no Mastodon sabe que eu estava de férias, durante as festas de fim de ano, no Brasil. Enquanto estive lá, deixei meu carro emprestado pra um grande amigo na Suécia.
Quando voltei e peguei o carro, notei algo diferente: minha bunda estava quentinha.
Só olhando no painel que vi que estava ativado o aquecimento do assento. Eu nem sabia que o carro tinha isso. Mas algo maravilhoso durante o inverno.
All we need is lov... bunda quente! All we need is bunda quentinha durante o inverno.
Totais de transporte durante 2024
2 de Janeiro de 2025, 16:49 - sem comentários ainda
Eu não sei bem o motivo, mas esse fim de ano o Google não mandou mais os dados totalizados de meios de transporte. E não tem mais como pegar os valores pelo browser. Só pelo app.
Eu queria saber quanto pedalei no total durante 2024. Então precisei fazer manualmente uma tabela e cálculo. Chato, mas nada de absurdo.
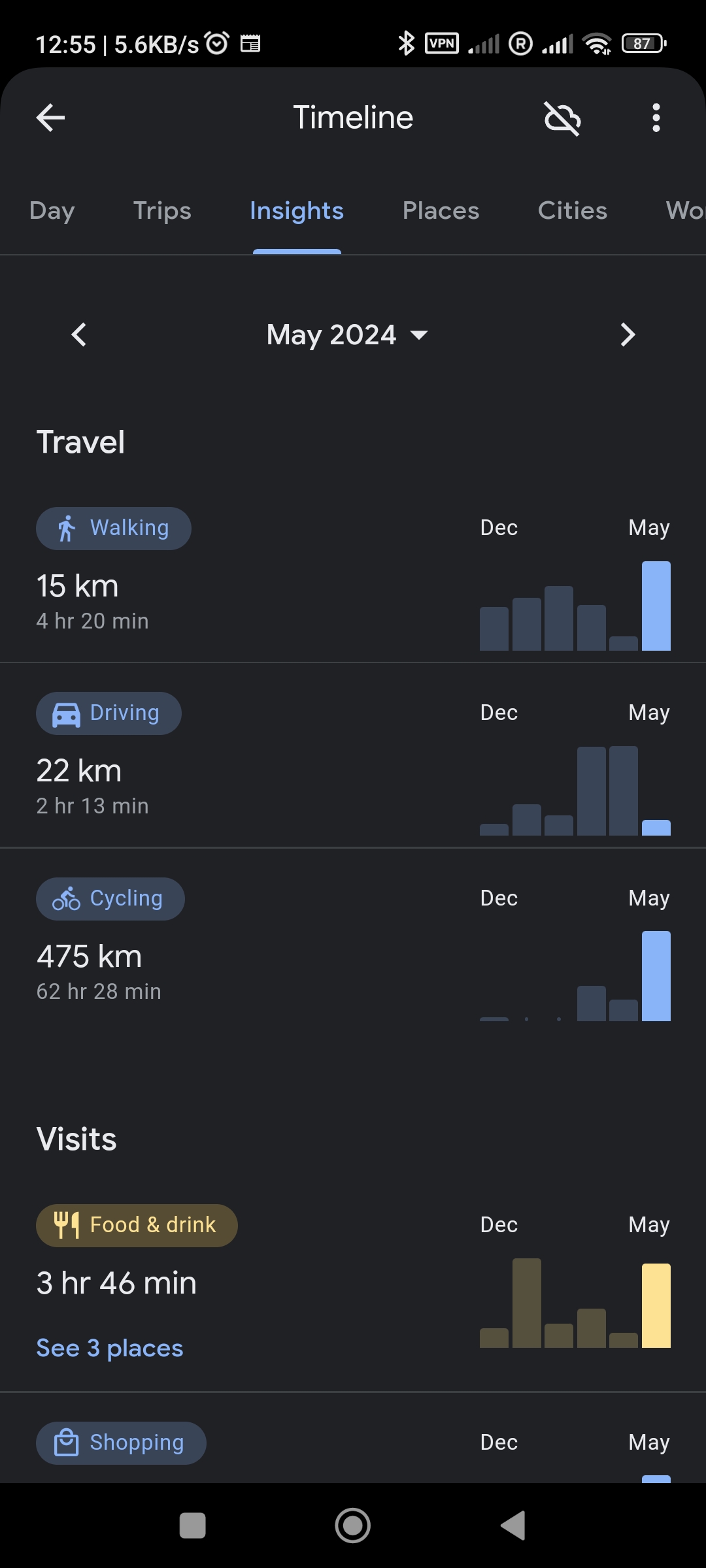
Os resultados foram os seguintes (dados em Km):
table, th, td { border: 1px solid black; border-collapse: collapse; align: center; margin-left: auto; margin-right: auto; }| Mês | Carro | Bicicleta | Transporte público | Avião | Motocicleta | Andando |
| Janeiro | 43 | - | 71 | - | 11 | 9 |
| Fevereiro | 28 | - | 182 | 2577 | - | 11 |
| Março | 124 | 187 | - | - | - | 7 |
| Abril | 125 | 113 | 33 | - | - | 2 |
| Maio | 22 | 475 | - | - | - | 15 |
| Junho | 1153 | 244 | 33 | - | - | 15 |
| Julho | 591 | 157 | 47 | - | - | 30 |
| Agosto | 220 | 254 | 31 | - | - | 7 |
| Setembro | 46 | 157 | 99 | 2173 | - | 25 |
| Outubro | 166 | 135 | 25 | - | - | 6 |
| Novembro | 173 | 130 | 116 | - | - | 14 |
| Dezembro | 512 | 113 | 20 | 10935 | - | 6 |
E fiz um programa em python, dentro do ipython, pra gerar os resultados (e também pra fazer depois essa tabela aqui em html):
In [48]: def soma_coluna(coluna):
...: soma = 0
...: for line in lines:
...: p = line.split("|")
...: try:
...: soma += int(p[coluna])
...: except TypeError:
...: pass
...: except ValueError:
...: pass
...: return soma
O resultados totais:
- Carro: 3203 Km
- Bicicleta: 1965 Km
- Transp. Público: 657 Km
- Avião: 15685 Km
- Motocicleta: 11 Km
- Andando: 147 Km
Confesso que fiquei decepcionado. Com 475 Km pedalados em maio, eu achei que ia bater os 3000 Km em 2024. Nem 2500 Km eu cheguei.
No artigo pedal forte de 2023 em dados do Google, é possível ver que também pedalei em torno de 2000 Km. Existe alguma divergência nos dados do Google, porque tenho 2 contas (uma free tier e outra paga), mas não acho que mudaria muita coisa. E não tive paciência de ficar catando dado mês-a-mês da outra conta.
Alguns dados parecem incorretos. Eu por exemplo não andei de moto em janeiro. Esse é o mês em que está tudo de baixo de neve na Suécia. Mas usei a moto pra ir trabalhar em outubro. Então pode ser que o dado da moto seja uma bicicleta na verdade (bem provável), mas e os dados da motocicleta devem ter ido parar na do carro em outubro. Não faria muita diferença nos dados totais.
Atualizando os artigos mais lidos
2 de Janeiro de 2025, 0:34 - sem comentários ainda
Só agora percebi que tinha um "artigos mais lidos de 2022" no topo do site. Atualizei pra mostrar os resultados de 2024.
Só levei algum tempo pra achar onde fazia isso. E não, não foram 2 anos pra achar. É que eu realmente não tinha percebido que isso estava no topo do site.
E no apagar de luzes de 2024...
26 de Dezembro de 2024, 12:56 - sem comentários ainda
E no fim de 2024, porque não fechar o ano com um ataque de DoS? Aparentemente alguém achou isso uma boa ideia. Ao menos o site não foi afetado.
Claro que também podem ter sidos acessos legítimos. Principalmente no https://linux-br.org mas eu particularmente não boto muita fé nisso.
Uma pausa pro fim do ano
25 de Dezembro de 2024, 15:20 - sem comentários aindaDepois de um ano muito louco, finalmente é tempo pra uma pausa pra descansar.

