


Mundo Docker: Iniciando com Pods
9 de Março de 2017, 16:08 - sem comentários aindaOlá pessoal,
Hoje quero fugir um pouco do tema “Docker” e quero mostrar para vocês um pouco mais de “Kubernetes”. Em dois posts anteriores mostrei como era complicada a instalação e configuração do Kubernetes caso não quizesse usar AWS ou Google Cloud. Com a comunidade sempre mostrando o quanto a instalação do Kubernetes era sempre trabalhosa, a partir da versão 1.4 foi criado o utilitario “kubeadm” que é utilizado para realizar a instalação de um cluster de Kubernetes de maneira rápida e fácil possibilitando assim uma maneira fácil de instalação e assim aderiando mais pessoas utilizando a ferramenta.
Passo 1 – Vamos iniciar agora a instalação do Kubernetes em alguns passos simples e depois vamos realizar algumas operações básicas para que você possa conhecer mais sobre essa ferramenta tão poderosa.
apt-get update && apt-get install -y apt-transport-https
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat < /etc/apt/sources.list.d/kubernetes.list
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF
apt-get update
# Install docker if you don't have it already.
apt-get install -y docker.io
apt-get install -y kubelet kubeadm kubectl kubernetes-cni
Passo 2 – Parecido com a sintaxe do comando para iniciar um cluster com o “docker swarm” com o comando abaixo vamos estar iniciando o cluster com Kubernetes. Caso tenha 2 placas de redes em seu servidor você poderá especificar qual deseja utilizar com --api-advertise-addresses <ip-address> passando como parâmetro para o comando kubeadm init
Na saída do comando será possível visualizar, no final a instrução para você adicionar um outro nó ao seu cluster, para isso basta você repetir o passo 1 em seu outro nó e colar a saída do comando acima onde mostra:
kubeadm join --token=<token> <master-ip>Após realizar os passos acima você estará com seu cluster de kubernetes quase pronto, porém ainda para que você possa fazer funcionar o seu cluster perfeitamente, você ainda precisa que seja instalado um plugin de rede para que o cluster de Kubernetes esteja a funcionar 100% para isso basta você executar:
kubectl apply -f https://git.io/weave-kube
Nesse caso o plugin escolhido foi o do Weave. Agora pronto estamos com nosso cluster de Kubernetes no ar e podemos começar a realizar as operações básicas em um cluster. Para isso vamos iniciar trabalhando com Pods.
Se você não sabe ainda os principais componentes do Docker, então você pode acompanhar um outro post nosso que fala sobre isso aqui. Então vamos por a mão na massa:
Com o comando kubectl é possivel fazer todas as operações que precisamos que sejam feitas em caso de lidarmos com containers. Então para listarmos os Pods que temos criados podemos executar o comando:
kubectl get pods Isso irá trazer os pods que foram criados no Namespace default. Namespaces são clusters virtuais dentro de um cluster físico, então eu posso ter dezenas de Namespaces em 1 cluster de kubernetes e em cada Namespace ter diversos Pods nos quais possuem total isolamento entre eles. Com namespace então eu posso limitar recursos como: CPU, Memória, Disco e Rede. Para que eu liste todos os Pods criados em todos os namespaces basta eu executar:
kubectl get pods --all-namespaces Para criar um Pod com uma imagem do Node.Js por exemplo você utiliza:
kubectl run --image=ghost --port=2368Estou utilizando a porta 2368, pois é a que está com o EXPOSE no Dockerfile. Também é possivel criar 1 Pod com n container no caso você deve utilizar o parâmetro --replicas
kubectl run node --image=ghost --replicas=5 --port=2368Nesse caso será criado os cinco containers no Docker porém apenas 1 Pod estará visivel no Kubernetes. Agora para que possamos acessar a nossa aplicação através do Browser devemos expor a porta 2368 para alguma porta do Host, o mesmo conceito do Docker, porém sintaticamente de uma forma diferente. Para isso utilizamos o comando:
kubectl expose deployment node --target-port=2368 --type=LoadBalancerCom o comando acima estamos dizendo para o Kubernetes pegar alguma porta livre no host e redirecionar o tráfego para a porta 2368 dentro do container e que o tipo de envio seja um LoadBalancer entre as replicas que eu mandei criar, então no caso das 5 réplicas que foram criadas acima, cada requisição será enviada para uma replica diferente da outra.
Mais para frente entraremos mais a fundo no Kubernetes, mas agora quando executamos o comando kubectl expose o Kubernetes criou um service de forma abstrata, podemos agora de forma resumida dizer que um service tem o papel de Habilitar um endpoint para que o usuário consiga acessar a aplicação". Então se você executar o comando:
kubectl get servicesVocê irá ver algo parecido com isso:
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
node 10.100.162.143 2368:31529/TCP 10s
Então a porta para que possamos acessar nossa aplicação será a porta 31529
Conforme criamos os primeiros posts sobre como criar containers, imagens e coisas mais simples com Docker, começaremos a fazer também com o Kubernetes, então vamos evoluir cada vez mais o conteúdo para que possa ser útil tanto para as pessoas que estão pensando em começar a usar, como também as que estão usando a um certo tempo.
Obrigado e fique ligado, pois em breve estaremos lançando novidades para os nossos leitores que estão se cadastrando em nossas Newsletter.
Grande abraço!
Mundo Docker: Docker EE e CE
6 de Março de 2017, 15:16 - sem comentários aindaOi Pessoal!
No último dia 02 de março, o Docker anunciou uma grande mudança em sua plataforma, lançando oficialmente a versão enterprise da engine de containers mais utilizada atualmente. Mas o que muda? Responderemos isso e mais algumas outras dúvidas neste post!
Esse movimento adotado pelo Docker em, dividir, as versões da sua engine é algo já esperado pela comunidade, e para alguns veio até tarde. Mas por que isso agora? Por um motivo simples, produto. O Docker vem já algum tempo sendo desenvolvido como uma plataforma, agregando a cada nova release alguma correção que resolve um problema ou uma feature que melhora algum aspecto da engine.
Agora temos claro as linhas de trabalho do Docker, e como serão realizadas as atualizações na plataforma. As entregas de novas features, correção de bug, etc, seguiram a mesma linha adotada por outras empresas, ou seja, correção de bug e fix mais frequentes do que novas features, com isso a comunidade não precisará aguardar tanto tempo para ter uma correção já na engine.
Para ficar mais claro, dá uma olhada nessa imagem:

Fonte: https://blog.docker.com/2017/03/docker-enterprise-edition
Como você pode notar, as entregas para a versão community serão mais frequentes, e serão baseadas em correções e fix, tendo uma cadência mensal. Já entregas que envolvem novas features ou mudanças significativas nas engine serão realizadas a cada três meses. Já a versão enterprise terá apenas entregas trimestrais, com correções e novas features (caso tenha é claro) e o suporte será de um ano, baseado na data de lançamento.
Mas por que essa agora?
Há algum tempo estamos divulgando, ensinando e ajudando diversos públicos ao uso do Docker, tendo em vista versatilidade dessa plataforma, é claro e obvio a necessidade de adaptação do modelo de negócio para atender esses públicos, por exemplo:
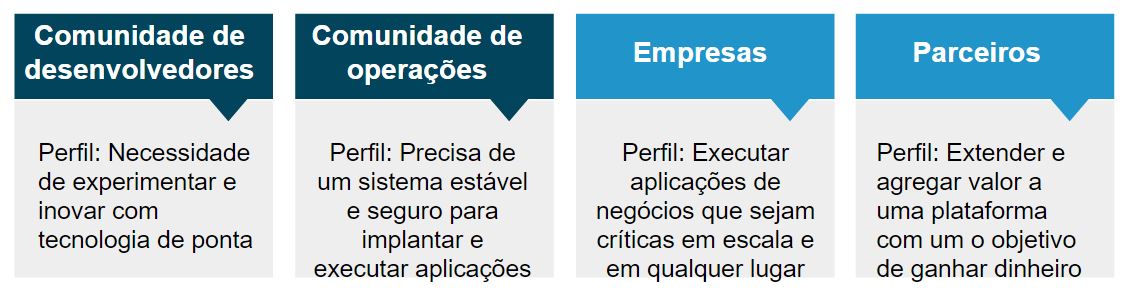
Note que são perfis diversos, com necessidades e expectativas diferentes, mas em algum momento complementares. A versão enterprise do Docker visa o público que não quer apenas brincar, mas sim colocar em produção e disponibilizar para cliente.

Na imagem acima temos um apanhado geral das diferenças e onde cada versão é aplicada. Isso quer dizer que não posso colocar o Docker CE em produção? Não, isso quer dizer que se você usar a versão enterprise terá mais facilidade, já com a versão community será possível mas você terá mais trabalho.
Mudou o nome?
Sim, a versão community será algo parecido com isso:
# docker -vDocker version 17.03.0-ce, build 60ccb22
Não teremos mais a nomenclatura de 1.xx, teremos então: ano.mes com a distinção entre CE e EE.
Tem mais alguma coisa nova?
Sim!!! Você já deve ter visto no anuncio oficial, agora há uma forma de você certificar seu ambiente seguindo as diretrizes do Docker, está disponível a Docker Store, um hub para publcação de recursos oficialmente homologados pelo Docker. Com isso, se você desejar criar um plugin para o Docker, por exemplo, você pode, atendendo uma série de requisitos, ter este plugin homologado e com certificado do Docker, o que obviamente aumenta sua relevância para quem usa.
Mas o que o Docker quer com isso? Te lembra daquelas imagens ali de cima, onde eram ilustrados os diferentes públicos que o Docker atende? Pois bem, dessa forma o Docker provê um recurso oficial, homologado e com o selo de aprovação deles para plugins, imagens, S.O, etc., atendendo assim a uma necessidade do mundo enterprise: “É confiável? Quem mantém?” dentre outras questões que este publico levanta no momento de decidir entre tecnologias.
Resumo, sim, o Docker acaba de se dividir em Community e Enterprise, até onde as coisas legais estarão na versão community só Deus sabe, mas a tendência é que sempre tenhamos com o que brincar. E claro, para quem não quer perder tempo fazendo tudo na mão, existe a enterprise, que facilita tudo o que é possível.
Ufa, agora sim acabou 
Nos ajude divulgando o blog! Grande abraço!
Mundo Docker: Docker Secrets
21 de Fevereiro de 2017, 12:19 - sem comentários aindaOi pessoal!
Para o artigo de hoje, contamos com a ajuda de um grande amigo nosso, o Wellington F. Silva, que colocou em seu blog um texto muito bacana sobre o que é e como funcionam as secrets no Docker 1.13. No decorrer desse post entenderemos como essa nova funcionalidade trabalha, sua origem e claro, o impacto disso em nosso dia-a-dia, #vamoslá?
O que é o secret?
Quando estamos trabalhando em um projeto e precisamos passar informações sensíveis para o ambiente, tais como senhas, chaves privadas, tokens, chaves de APIs e afins sempre passamos pelo problema de não podermos deixar no controle de versão e devemos sempre utilizar uma maneira segura de trafegar esses segredos.
Muitas vezes acabamos trabalhando com variáveis de ambiente para guardar essas informações, o que não é recomendado por alguns motivos.
Diogo Monica que é um dos engenheiros de software da Docker mencionou em um comentário que variáveis de ambiente quebram o princípio de “least surprise” e podem levar a eventuais vazamentos de segredos já que estão acessíveis de várias maneiras, tais como linked containers, através do *docker inspect*, de processos filhos e até de arquivos de logs já que em caso de exceptions da aplicação muitos frameworks fazem o dump do contexto, inclusive o valor das variáveis de ambiente no arquivo de log.
Um pouco da história
Em Janeiro de 2015 houve uma proposta de adicionar o comando `docker vault` numa alusão ao Vault Project da Hashicorp para fazer a gerencia de segredos dentro do próprio Docker. Segue o link para a issue 10310 no GitHub. A discussão evoluiu e virou a issue 13490, onde trataram do roadmap para o atual Docker Secrets.
Como funciona?
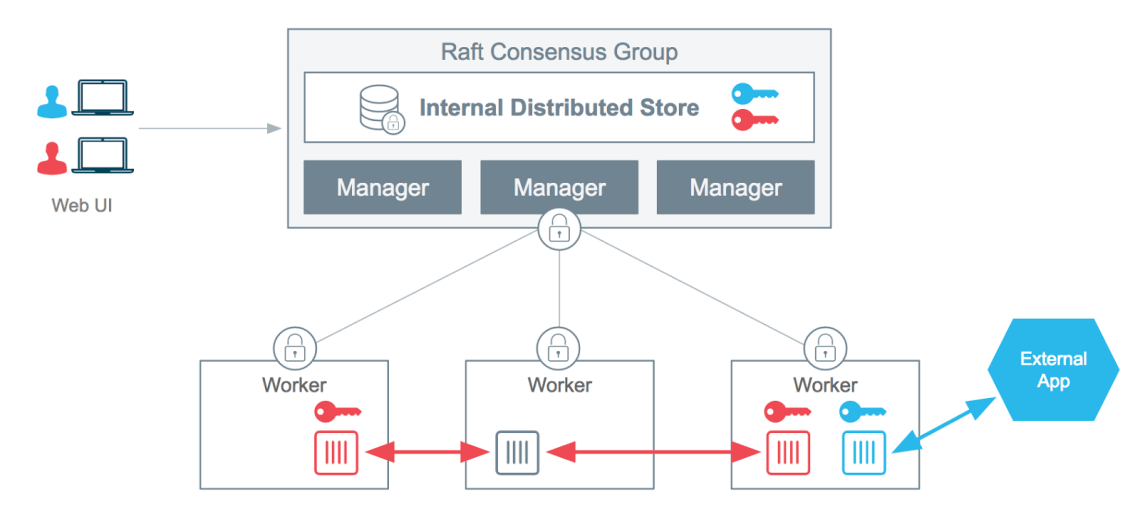
O Docker Secrets funciona como um cofre onde você pode colocar coisas sensíveis lá e só que tem a chave do cofre consegue utilizar, no caso essa chave é designada aos nós dos serviços que a chave for atribuída.
Dicas
- Só funciona no Swarm Mode onde toda a comunicação entre os nós é por padrão encriptada.
- Se utiliza do algoritmo de RAFT para persistir o segredo de forma encriptada por todos os nós managers e distribuir aos containers que fizerem parte do serviço ao qual a chave for atribuída.
Segue diagrama da própria Docker:
Criando um secret
Podemos criar um secret de duas maneiras, usando o STDIN:
$ echo "ConteudoDoSecret" | docker secret create um-secret -
Ou lendo um arquivo:
$ docker secret create novo-secret $HOME/senhas.txt
Listando, removendo e demais opções
Para listar as secrets disponíveis:
$ docker secrets ls ID NAME CREATED UPDATED 8ulrzh4i1kdlxeypgh8hx5imt um-secret 3 minutes ago 3 minutes ago n95fprwd2trpqnjooojmpsh6z novo-secret About an hour ago About an hour ago
Demais opções do que fazer com os secrets como remover, inspecionar, etc podem ser listadas com o help:
$ docker secret --help
Usando o secret criado
Podemos criar um serviço usando um secret criado com o comando:
$ docker service create --name demo --secret um-secret mysql:5.7
Podemos remover um secret de algum serviço existente
$ docker service update --secret-rm um-secret demo
Ou podemos adicionar um secret a algum service que esteja de pé:
$ docker service update --secret-add novo-secret demo
Quando atrelamos um secret a um service podemos então acessar qualquer um dos containers que estejam rodando nesse service no path /run/secrets. Dentro do container nesse path vai existir um arquivo plain text com o nome igual ao definido no nome do secret e com o conteúdo desejado, o secret em plain text. No nosso caso seria no path /run/secrets/novo-secret.
Bem legal não é? Ajude divulgando o blog, e fique ligado teremos muitas novidades em breve, então se não se inscreveu em nossa newsletter, inscreva-se ;). Até a próxima.
Fonte: http://dumpscerebrais.com/2017/02/como-trabalhar-com-secrets-no-docker-1-13-x/
Wellington Silva: Como trabalhar com Secrets no Docker 1.13.x
15 de Fevereiro de 2017, 5:22 - sem comentários aindaNo dia 18 de janeiro de 2017, há menos de um mês foi lançada a versão 1.13 do Docker com uma porrada de novas e matadoras funcionalidades. Uma das que eu mais gostei foi a possibilidade de gerenciar secrets no Swarm Mode e é sobre ela que vou discorrer nesse artigo.
O que é o secret?
Quando estamos trabalhando em um projeto e precisamos passar informações sensíveis para o ambiente, tais como senhas, chaves privadas, tokens, chaves de APIs e afins sempre passamos pelo problema de não podermos deixar no controle de versão e devemos sempre utilizar uma maneira segura de trafegar esses segredos.
Muitas vezes acabamos trabalhando com variáveis de ambiente para guardar essas informações, o que não é recomendado por alguns motivos.
Diogo Monica um dos software engineers da Docker cita em um comentário que variáveis de ambiente quebram o princípio de “least surprise” e podem levar a eventuais vazamentos de segredos já que estão acessíveis de várias maneiras, tais como linked containers, através do docker inspect, de processos filhos e até de arquivos de logs já que em caso de exception muitos frameworks fazem o dump do contexto, inclusive o valor das variáveis de ambiente no arquivo de log
Um pouco da história
Em Janeiro de 2015 houve uma proposta de adicionar o comando docker vault numa alusão ao Vault Project da Hashicorp para a gerencia de segredos dentro do próprio Docker. Segue o link para a issue 10310 no GitHub.
A discussão evoluiu no issue e virou a issue 13490 onde trataram do roadmap para o atual Docker Secrets.
Como funciona?
O Docker secrets funciona como um cofre onde você pode colocar coisas sensíveis lá e só que tem a chave do cofre consegue utilizar.
Dicas
Só funciona no Swarm Mode onde toda a comunicação entre os nós é por padrão encriptada.
Se utiliza do algoritmo de RAFT para persistir o segredo de forma encriptada por todos os nós managers.
Criando um secret
Podemos criar um secret de duas maneiras, usando o STDIN:
$ echo "ConteudoDoSecret" | docker secret create um-secret -
Ou lendo um arquivo:
$ docker secret create novo-secret $HOME/senhas.txt
Listando, removendo e demais opções
Para listar as secrets disponíveis:
$ docker secrets ls
ID NAME CREATED UPDATED
8ulrzh4i1kdlxeypgh8hx5imt um-secret 3 minutes ago 3 minutes ago
n95fprwd2trpqnjooojmpsh6z novo-secret About an hour ago About an hour ago
Demais opções do que fazer com os secrets como remover, inspecionar, etc.
$ docker secret --help
Usando o secret criado
Podemos criar um serviço usando um secret criado com o comando:
$ docker service create --name demo --secret um-secret mysql:5.7
Podemos remover um secret de algum serviço existente
$ docker service update --secret-rm um-secret demo
Ou podemos adicionar um secret a algum service que esteja de pé:
$ docker service update --secret-add novo-secret demo
Quando atrelamos um secret a um service podemos então acessar qualquer um dos contêineres que estejam rodando nesse serviçe e acessar o path /run/secrets. Dentro do contêiner vai existir um arquivo plain text com o nome igual ao definido no nome do secret e com o conteúdo desejado, o secret em plain text. No nosso caso seria no path /run/secrets/novo-secret.
Exemplo
Segue exemplo criando e utilizando um secret como senha para um banco de dados MySQL, ao final nós conectamos ao MYSQL usando o a senha passada como secret para a criação do serviço.
Até a próxima.
Mundo Docker: Docker Stack e Deploy
14 de Fevereiro de 2017, 11:23 - sem comentários aindaOi Pessoal,
Nós já conversamos sobre o Docker 1.13 aqui, agora vamos explorar um pouco mais sobre essa funcionalidade que saiu do modo experimental e tornou-se parte da engine estável do Docker, sim estamos falando do docker stack/deploy. Mas antes, recomendo fortemente você ler este post aqui sobre docker compose v3, ele é muito, mas muito importante mesmo para os exemplos que veremos neste post.
Agora com o Docker 1.13 é possível você portar suas aplicações do compose para o Swarm, e isso graças a funcionalidade de deploy disponível na engine. Seu funcionamento é bem simples, basta você informar na execução do comando o diretório de onde está o seu arquivo compose, e o nome da aplicação, se lembra que falei que era muito importante olhar esse post? Pois bem, não adianta você ter um compose escrito para a versão 2 e tentar utilizar aqui, será necessário você se altere para as novas regras da versão 3 para que seja possível a criação de sua stack pelo docker deploy. Mas digamos que você já tem seu arquivo pronto na versão 3, vamos pegar o exemplo do outro post, basta executar:
$ docker deploy --compose-file docker-compose.yml app
O retorno desse comando será
$ docker deploy --compose-file docker-compose.yml app Creating network app_default Creating service app_nginx Creating service app_redis
Dessa forma foram criados uma rede e dois serviços, o mesmos definidos no arquivo compose. Para obter mais informações da stack, você pode executar os comandos:
$ docker stack ls NAME SERVICES app 2
Com o stack ls, será retornado todas as stacks que você criou, neste caso retornou apenas a “app” e informa também quantos serviços existem para essa stack, com este comando:
$ docker stack ps app ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS xb02xrua71db app_redis.1 redis:latest node1 Running Running 7 minutes ago lm7k8obhncyl app_nginx.1 nginx:latest node1 Running Running 7 minutes ago jh65f9scx0cq app_nginx.2 nginx:latest node1 Running Running 7 minutes ago
Você visualizará mais informações sobre a stack, como por exemplo o id de cada container, imagem utilizada, nome do container, nó onde está executando e claro o estado de cada container. Você pode ainda, executar o comando:
$ docker stack services app ID NAME MODE REPLICAS IMAGE g3i4f4erympf app_nginx replicated 2/2 nginx:latest s11w093eraxz app_redis replicated 1/1 redis:latest
Para ter a visualização de sua stack no mesmo formato dos serviços (docker service ls).
O que fizemos até aqui foi portar uma stack do docker-compose para o cluster de swarm.
“Ahh mas como assim?”
Bom se você pegar esse mesmo arquivo de compose e executar: docker-compose up -d, ele funcionará também, sem erro, sua stack iniciará e ficará disponível para uso, MAS, não em cluster :), você continuará utilizando o docker-compose da mesma forma que antes, sem os benefícios do Swarm. Apenas com o docker deploy é que você poderá fazer o deploy e gerenciamento de sua stack dentro do cluster de swarm.
“Ok, entendido, mas como eu escalo agora a minha stack? Antes eu executava: docker-compose scale app=3, como faço isso com o docker stack?”, não se preocupe, você continuará tendo a possibilidade de escalar a sua stack, vamos lá: Já sabemos que o docker deploy criar todos os serviços necessários para a stack, certo? Pois bem, para escalar algum componente da sua stack, basta você escalar o serviço, da mesma forma como se você estivesse manipulando um serviço dentro do swarm, veja:
$ docker service ls ID NAME MODE REPLICAS IMAGE cnnabnpqkjvy app_redis replicated 1/1 redis:latest pcn4urntqn8l app_nginx replicated 2/2 nginx:latest
Agora vamos escalar o serviço de nginx da minha stack app:
$ docker service scale app_nginx=4 app_nginx scaled to 4
E o resultado é:
$ docker service ls ID NAME MODE REPLICAS IMAGE cnnabnpqkjvy app_redis replicated 1/1 redis:latest pcn4urntqn8l app_nginx replicated 4/4 nginx:latest
Ou seja, escalei apenas o nginx.
“Ok, muito bonito, mas como eu acesso a minha stack?”
Boa pergunta, mas é claro que há uma resposta, e é aqui que vem a parte mais legal ;).
Vamos voltar ao docker-compose.yml que usamos para criar essa stack, veja essas linhas:
nginx:
image: nginx
ports:
- 80:80
Preste atenção no parâmetro: ports, ali você define em qual porta o serviço vai ouvir, neste caso, o nginx estará trabalhando na porta 80, ou seja, o serviço no cluster de swarm estará disponível para acesso através da porta 80, e todos os nós do cluster, quando receberem alguma requisição na porta 80 encaminharão para o container que atende este serviço (utilizando uma das funcionalidade do docker swarm que é a rede de serviço em mesh).
Quando escalamos um serviço, dizemos ao docker para adicionar mais containers para atender as requisições que estarão sendo feitas para o mesmo, ou seja, teremos diversos containers atendendo um único recurso que é o serviço, e o swarm se encarrega de distribuir os acessos para todos os containers.
“Ta bom, me convenceu, mas como removo tudo agora pra fazer direito?”
Muito fácil, da mesma forma que o docker service, basta você executar:
$ docker stack rm app Removing service app_redis Removing service app_nginx Removing network app_default
E serão removidos todos os serviços, containers e rede que tenham sido criadas pela sua stack.
Interessante não? Esperamos que tenha sido útil, se ficou com dúvida nos avisa que ajudamos. Por hoje era isso, nos ajude divulgando o blog e fique atento, teremos mais novidades em breve ;).
Abraço!
