




Um pouco sobre a história dos bancos de dados – Parte II
24 de Outubro de 2017, 15:18 - sem comentários aindaOs anos 80 foram realmente incríveis, não?
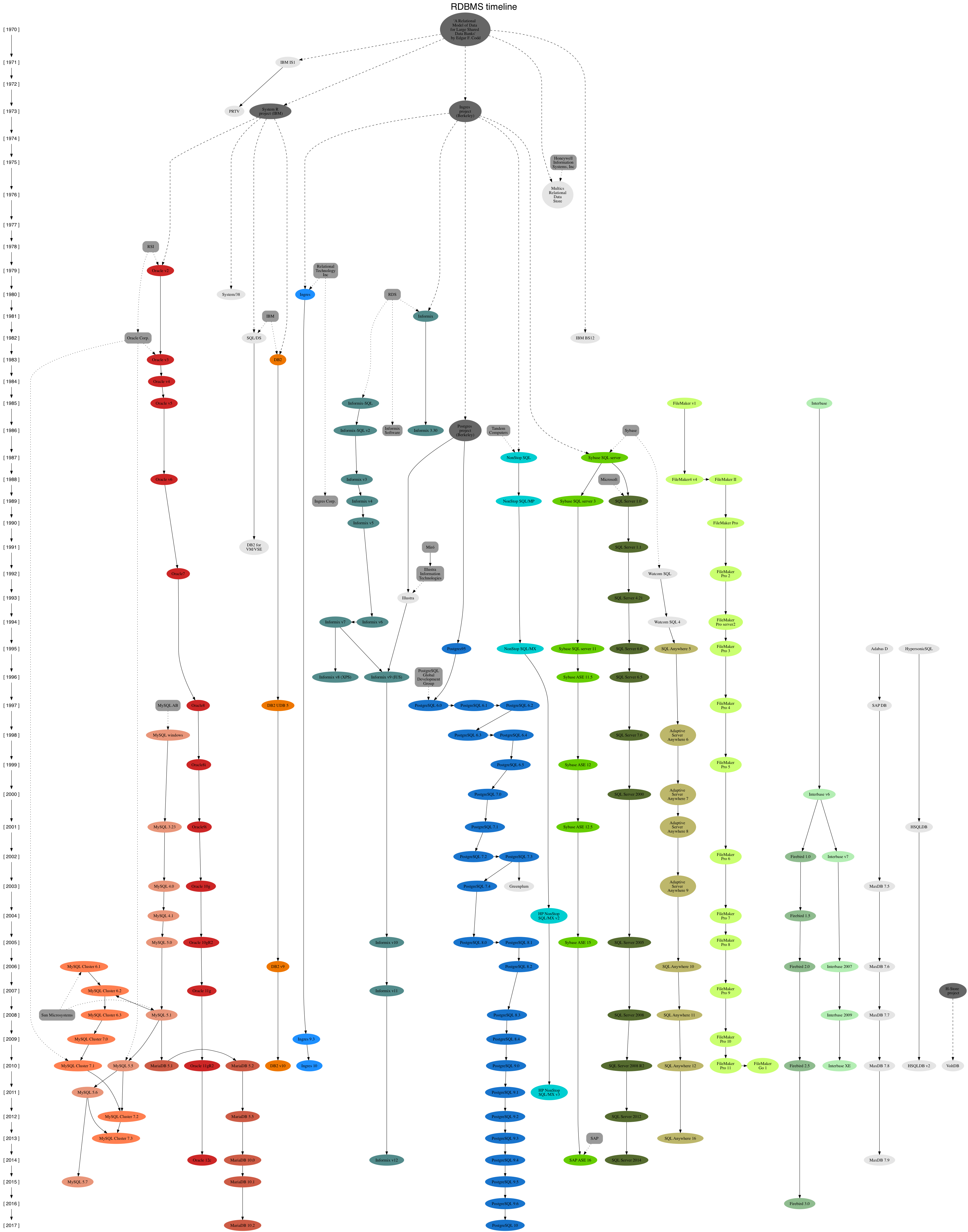
Na primeira parte falamos sobre as origens dos bancos de dados, passando pelas décadas de 60 e 70. Agora vamos continuar nossa saga pelos anos 80 e 90.
dBase
Na década de 80, com o lançamento do IBM PC, os microcomputadores deixam de ser brinquedos e entram em cena como uma alternativa de baixo custo para a informatização de empresas. Assim, surge ainda em 1979 o dBASE. Longe de ter a sofisticação dos bancos de dados relacionais, eles atenderam bem às demandas menores e tiveram muitas outras iniciativas baseadas nele como o Clipper, o FoxPro e toda uma família de clones conhecida como xBase.
Teradata
Também em 1979, foi lançado o Teradata, um banco de dados que praticamente criou o conceito de DataWarehouse. O Teradata era vendido como um banco de dados integrado com o hardware e utiliza a arquitetura de cluster do tipo “Shared Nothing” para escalar sua capacidade horizontalmente. Em 2011, o Teradata incorpora capacidades de Big Data com recursos de MapReduce por exemplo.
O padrão SQL
Na década de 90, os bancos de dados relacionais passam a povoar os microcomputadores em Unix e Windows também. Nesta época, os bancos de dados no estilo dBase começam a perder popularidade, enquanto os bancos de dados relacionais passam a dominar o mercado. O padrão SQL criado pela IBM é consolidado no ANSI SQL em 1986 e no padrão ISO SQL em 1987. Depois disso, várias versões do padrão ISO SQL são lançados: SQL-89, SQL-92, SQL-99, SQL-2003, SQL-2006, SQL-2008, SQL-2011 e SQL-2016. Nenhum banco de dados relacional incorpora plenamente todo o padrão, nem mesmo o SQL-99 é adotado plenamente, mas nos anos recentes é observado que um número maior de bancos de dados tem sido mais mais aderentes ao padrão.
Sybase
Em 1984, o Sybase é criado a partir da experiência com o Ingres. Em 1988, é feita uma parceria com a Microsoft para lançar uma versão do Sybase para o OS/2. Em 1993, a parceria com a Microsoft é desfeita e a Microsoft passa a vender a sua própria versão para o Windows, o MS SQL Server. Em 1996, o nome do banco de dados é trocado para ” Adaptive Server Enterprise” e em 2010 a SAP compra o Sybase. O Sybase teve grande destaque na década de 90 e voltou a se destacar com a aquisição pela SAP que tem utilizado o Sybase em seu ERP.
MS SQL Server
As primeiras versões do SQL Server nada mais eram que versões do Sybase portadas para o OS/2, um sistema operacional desenvolvido pela IBM e Microsoft para substituir o Windows, que acabou não vingando. Depois vieram as versões para o Windows NT. Com o rompimento com a Sybase em 1996, o MS SQL Server 6.0 foi a primeira versão lançada sem a mão da Sybase. Nas próximas versões, o código original passa a ser gradualmente reescrito até que no SQL Server 2005, o código original do Sybase já havia sido quase totalmente substituído. O SQL Server cresceu junto com a popularidade das versões do Windows para servidores se tornando o 3º maior banco de dados, logo atrás do Oracle e do MySQL. Recentemente a Microsoft anunciou que as novas versões do MS SQL Server irão rodar também em Linux, algo impensável nos anos 2000, uma vez que a Microsoft foi uma grande opositora ao Linux no passado. O sucesso da Azure, serviço de nuvem da Microsoft também tem ajudado a alavancar o SQL Server no mercado.
PostgreSQL
Após sair da universidade de Berkeley em 1982 para tentar comercializar uma versão proprietária do Ingres, o Sr. Michael Stonebraker volta à universidade em 1985 para criar uma versão “post-ingres”. Ele queria reescrever o Ingres do zero, procurando soluções para novos problemas encontrados nos bancos de dados da década de 80. Assim em 1986, nasceu o Postgres, com várias características novas, com destaque para a flexibilidade e capacidade de extensão. Em 1989, foi lançada a primeira versão do Postgres que continuou a ser desenvolvido em Berkeley até 1994, quando a universidade de Berkeley publica o código fonte na internet utilizando a licença livre BSD. O Sr. Michael Stonebraker sai novamente de Berkeley e cria o Illustra, uma versão proprietária do Postgres que em 1997 é comprada pela Informix, que por sua vez foi comprada pela IBM em 2001.
Em 1994, dois alunos graduados em Berkeley adicionam a linguagem SQL ao Postgres que passa a ser chamado depois de PostgreSQL (embora ainda seja oficialmente aceito o nome anterior, Postgres). A Partir de 1996, ele passa a ser mantido por uma comunidade de desenvolvedores independentes conhecida como PGDG ou PostgreSQL Global Development Group. Devido ao tipo de licenciamento do Postgres, dezenas de versões proprietárias foram criadas com o tempo, mas a versão livre mantida pelo PGDG continua sendo a mais utilizada, sendo hoje o 4º maior banco de dados.
Arquitetura Client/Server
Até meados da década de 80, a maior parte das aplicações e bancos de dados rodavam em um único computador, um mainframe ou um mini computador. Com o desenvolvimento dos microcomputadores, surgiram cada vez mais aplicações onde o banco de dados residia num computador de porte maior (como um UNIX ou depois um Windows Server) e a aplicação era distribuída em vários microcomputadores. Os bancos de dados relacionais, ao contrário do dBase, eram bastante eficientes neste tipo de arquitetura. Aplicações em MS Visual Basic e Delphi se alastraram em grande volume. Nessa época, os 3 maiores bancos de dados do mercado eram o Oracle, Sybase e Informix.
MySQL
Em 1993, o Sr. David Hughes queria um banco de dados para uma aplicação de monitoramento de rede. Ele queria utilizar um banco de dados relacional com a linguagem SQL. Eles tentaram criar uma interface SQL para o Postgres, que na época ainda usava o QUEL e o chamaram de miniSQL ou mSQL. Mas o Postgres era muito complexo e pesado para a tarefa que eles tinham em mente. Então eles criaram uma versão mais simples de um banco de dados que implementava apenas uma parte do SQL, feito para funcionar em hardwares bastante simples. O mSQL teve grande importância nos primórdios da WWW pois era simples, leve e rápido. Ele foi muito utilizado entre 1994 e 1997, quando foi superado pelo MySQL.
O MySQL foi criado em 1994 com a primeira versão lançada em 1995. Foi baseado no mSQL e manteve a mesma API, permitindo uma fácil migração do mSQL para o MySQL. O MySQL, teve enorme impacto na internet. A arquitetura LAMP (Linux, Apache, MySQL e PHP), foi o motor da “Internet 2.0”. Com o tempo foram sendo incorporadas novas funcionalidades SQL no MySQL, além de outros Storage Engines, característica peculiar do MySQL. Em 2008, a MySQL AB, companhia que criou o MySQL foi comprada pela SUN Microsystems. Em 2010, a Oracle compra a SUN. Após MySQL AB ser comprada pela SUN começaram a surgir novos forks do MySQL, movimento que se intensificou quando a Oracle comprou a SUN. Os forks mais conhecidos do MySQL hoje são o MariaDB, Percona Server e mais recentemente o Aurora da Amazon. A Oracle possui hoje os dois maiores bancos de dados do planeta, o Oracle Database e o MySQL.
O bancos de dados Objeto-Relacional
Na década de 90, as linguagens orientadas ao objeto como o Java da Sun começaram a fazer muito sucesso. Enquanto a Sun guiava o mercado rumo à internet com seus servidores Sparc e Sistema Operacional Solaris, outras linguagens como PHP, depois ASP, Python e Ruby espalharam a “Internet 2.0” ou a Internet dinâmica, com sites nas quais suas páginas são construídas dinamicamente com base nas informações dos seus bancos de dados. Apesar deste florescimento, os bancos de dados relacionais surgiram na era da programação estruturada. A ligação entre tabelas relacionais nos bancos de dados e objetos nas linguagens se tornou um problema que dificultou a vida dos programadores. Uma das soluções encontradas foi a criação de uma infinidade de ferramentas de ORM (Object Relational Mapping), como o famoso Hibernate. O problema das ferramentas de ORM é que elas funcionam muito bem para telas simples e operações CRUD, mas são um desastre em relatórios e transações complexas.
A outra solução encontrada foi a criação de bancos de dados que estendem a teoria relacional criada por Codd e criam formas mais naturais de armazenar objetos. O primeiro banco de dados a fazer isso foi o Postgres, já no seu projeto inicial em 1986. Tempos depois, os demais grandes bancos de dados relacionais também criaram extensões objeto-relacionais. Em 1999, é lançado o ISO SQL::1999 que define um padrão para estas extensões objeto-relacionais.
Houve também iniciativas mais ousadas criando bancos de dados puramente orientados a objetos. O banco de dados que teve maior sucesso nisso foi o InterSystems Caché. Com o tempo, os bancos de dados orientados ao objeto não fizeram tanto sucesso, seja por falta de uma teoria mais robusta para lhes darem sustentação, seja por falta de padronização ou por fim, por não apresentarem um desempenho semelhante aos bancos de dados relacionais. Ainda assim, em situações que manipulam dados complexos, eles encontraram um nicho de mercado.
Os teste de performance TPC
No começo da década de 90, os bancos de dados relacionais estavam com seu desenvolvimento a pleno vapor e passaram a estabelecer uma hegemonia global no mercado de bancos de dados. No entanto, cada fornecedor sempre alegou ser melhor que os demais. Os departamentos de marketing sempre foram muito criativos em estabelecer métricas muitas vezes obscuras nas quais o seu produto sempre aparece como líder de mercado. Ao fim e ao cabo, duas métricas poderiam ser facilmente verificáveis entre cada fornecedor: preço e desempenho.
Infelizmente, a história não é tão simples assim. Os custos de manutenção de um banco de dados podem envolver diferentes custos de licenciamento, suporte, compra de hardware, etc. Pior que isso é comparar o desempenho dos diferentes bancos de dados com um conjunto de operações idênticas que se assemelhem com a carga que um banco de dados recebe no dia-a-dia. Por fim, ainda existe um detalhe delicado: a licença de uso da maioria dos bancos de dados comerciais não permite que você publique o resultado de testes de performance sem a autorização do seu fornecedor. Tudo isso torna muito complicada a tarefa de escolher qual banco de dados suporta determinada carga e qual o custo para suportar esta carga.
O Transaction Processing Performance Council, ou simplesmente TPC, foi criado com a intenção resolver esta bagunça. Criaram um teste padrão chamado TPC-A para medir a performance em bases OLTP imitando uma transação bancária. Depois, vieram novas versões com o TPC-B e o TPC-C. A última versão de testes em com carga OLTP foi o TPC-E, um teste mais complexo e completo para os dias atuais. Infelizmente, apenas encontramos testes do MS SQL Server com o TPC-E, portanto não é possível comparar estes testes com outros fornecedores. Também criaram testes para outros tipos de carga como sistemas web, o já aposentado TPC-W, e o TPC-H para datawarehouse, entre outros. Até o começo dos anos 2010 a maioria dos grandes bancos de dados comerciais possuíam testes publicados no site do TPC e eram um recurso valioso para comparar preço e performance de bancos de dados.
Um dos problemas do TPC era que os bancos de dados livres nunca publicaram um único teste no TPC. Os custos para realizar os testes são muito altos e não temos nenhum teste com MySQL, PostgreSQL ou Firebird por exemplo. Outro problema é que no começo em meados de 2010, alguns fornecedores como a Oracle deixaram de publicar testes no TPC. O último teste com Oracle disponível é um TPC-H de 2014 utilizando Oracle 11G. Portanto, hoje em dia, ficamos sem parâmetros de comparação para preço e desempenho. Acreditar nos dados publicados pelos fornecedores em geral é acreditar em contos de fada…
Continua na Parte III
Um pouco sobre a história dos bancos de dados – Parte I
24 de Outubro de 2017, 13:42 - sem comentários aindaPorque a história importa sim!
Era uma vez um professor de informática que dizia que falar sobre a história da informática era irrelevante e iria passar rápido pela matéria. Só estava fazendo isso porque estava no currículo. É claro que eu tive de discordar. Conhecer a história nos dá uma compreensão melhor de como chegamos até aqui. As coisas nem sempre foram iguais. Muita gente esquece que as coisas mudam, olhar tudo em perspectiva nos faz entender melhor o mundo onde vivemos. Tem gente que se esquece, por exemplo que a prova de que a terra não é plana não veio de uma conspiração da NASA e sim da primeira circunavegação em 1521. Ou que os primeiros computadores surgiram na II Guerra Mundial. Se temos mais de 80 anos do surgimento do ENIAC, muita coisa mudou de lá para cá e alguns episódios curiosos nos fazem entender como chegamos aqui e nos dão algumas pistas do que pode acontecer num futuro não muito distante.
Os primeiros computadores
Trabalhar com grandes volumes de informações é um problema da civilização moderna. Organizar um conjunto de livros numa biblioteca ou o estoque de produtos de uma grande loja envolve catalogar, armazenar e ordenar um grande volume de informações. E chega um momento que um grande arquivo de metal não dá mais conta do recado.
Foi assim que algumas tecnologias modernas surgiram. A grande IBM surgiu com máquinas para processar o censo populacional dos EUA.
O uso dos bancos de dados em computadores teve que esperar um bocado. No começo, os primeiros computadores eletrônicos da década de 40 (houve algumas tentativas de computadores mecânicos e também eletromecânicos antes) como o Z3 na Alemanha, o Colossus na Inglaterra e o ENIAC nos EUA ainda utilizavam válvulas, tinham uma memória RAM muito limitada e não havia armazenamento em meios magnéticos, sejam fitas ou discos. O que havia nesta época eram os cartões perfurados. Sendo assim, trabalhar com grandes volumes de dados ainda era algo muito complicado.
Os primeiros bancos de dados
No final da década de 50 a IBM lançou os primeiros discos rígidos do mercado. Para se ter uma ideia, os discos do IBM 350 RAMAC tinham o tamanho de duas geladeiras, pesava quase uma tonelada, tinham capacidade útil de menos de 4MB e uma durabilidade de 3 mil horas de uso. O desenvolvimento dos discos rígidos na IBM foi inicialmente tímido, uma vez que ela estava ganhando muito dinheiro vendendo sistemas com cartões perfurados ainda. Ao mesmo tempo, na década de 60 os mainframes e também os “mini computadores” conquistaram o mundo dos negócios em grandes empresas e no governo. Logo surgiu uma grande demanda pelos discos rígidos e eles se tornaram mais rápidos, menores, com maior capacidade, mais confiáveis e mais baratos.
COBOL
Da mesma forma, no final da década de 50 surgiu a primeira linguagem de programação voltada para o o mundo dos negócios: o COBOL. O COBOL trabalhava com dados num formato posicional, onde os dados eram numerados numa tabela na qual cada campo ocupava um número fixo de caracteres. O COBOL teve enorme impacto na informática apesar das críticas. A sua forma de trabalhar com dados permitiu que aplicações trabalhassem com um grande volume para a época, mas todo o trabalho no controle dos dados era feito diretamente pela aplicação escrita em COBOL, não havia um sistema gerenciador de banco de dados.
O IDS (Integrated Data Store) foi o primeiro sistema gerenciador de banco de dados escrito para o COBOL criado em 1964 e utiliza assim como nos programas em COBOL o esquema de armazenamento em rede. Os bancos de dados em rede feitos para COBOL foram muito populares em mainframes e mini computadores até meados da década de 80.
IBM IMS
No final da década de 60, a IBM novamente entra no jogo para atender uma demanda da NASA, o banco de dados de partes e peças do projeto Apollo. Para isso, cria o IBM IMS (Information Management System) em 1966, com um esquema de armazenamento hierárquico, diferente do COBOL. O IMS tem longa vida dentro da IBM. A última versão do IMS foi lançada em 2015, ou seja, mais de 51 anos depois e continua sendo utilizado até hoje.
Nascem os bancos de dados relacionais
Enquanto a IBM estava investindo no IMS, em 1970 um de seus funcionários, o Sr. Edgar F. Codd, publica um documento intitulado “A Relational Model of Data for Large Shared Data Banks” descrevendo a teoria relacional. A IBM não deu muita bola para o trabalho do Sr. Codd. No entanto, algumas pessoas de outros escritórios da IBM gostaram das ideias e criaram os protótipos IBM IS1 entre 1970 e 1972, o IBM PRTV em 1973 e ainda o IBM BS12 em 1978. Fora da IBM, também surgiram outras experiências como o Ingres em 1973 e o MRDS em 1976.
IBM Db2
No entanto, foi em 1974 que a IBM cria um projeto chamado System R, para testar as ideias de Codd, no escritório de San José, Califórnia, onde o Sr. Codd trabalhava. Por incrível que pareça, o projeto não foi fiel às ideias do modelo relacional e foi deste projeto que surgiu a linguagem SQL. Isso foi motivo de muitas críticas à linguagem SQL, por ela não ser estritamente relacional. O System R foi comercializado pela primeira vez em 1977. Em 1981, foi lançado como IBM SQL/DS mas só em 1983 foi lançado o Database2 ou IBM Db2. O Db2 é até hoje o principal banco de dados em mainframes e utilizado principalmente por grandes instituições financeiras para bases transacionais de alta concorrência.
Ingres
É claro que a IBM demorou muito para lançar o Db2. E é claro, também, que o peso de tudo que a IBM lança no mercado tinha um peso enorme. O Ingres, criado nos laboratórios da universidade de Berkeley em 1973, criou a linguagem QUEL, baseado os trabalhos de Codd. Os próprios desenvolvedores do System R admitem que o QUEL era superior em vários aspectos em relação ao SQL. Mas o padrão de mercado se tornou a linguagem SQL e o QUEL, mesmo lançado 10 anos antes do DB2, não conseguiu superar o SQL. Apesar disso, como era um projeto com licença de software livre (a licença BSD da universidade de Berkeley), vários outros bancos de dados foram criados na década de 80 baseados no Ingres, entre eles o Sybase e o SQL Server. Em 1985, o Ingres deixa a universidade de Berkeley e se torna um produto comercial. Em 2006, o Ingres tem o código fonte aberto pela Computer Associates e em 2011 é comprada pela Actian Corporation.
Oracle
Já a Oracle, começou os trabalhos na mesma época, mas derivou seu banco de dados diretamente dos trabalhos do Ingres e do System R lançando sua primeira versão em 1978. Desta forma a Oracle apesar de lançar sua primeira versão 5 anos depois do Ingres, utilizou a linguagem SQL que futuramente se tornaria a linguagem padrão para os bancos de dados relacionais. Já em 1979, a Oracle já era superior ao System R e na metade da década de 80, a Oracle derruba o seu maior competidor o Ingres. Hoje, o valor de mercado da Oracle é maior que o da própria IBM, sendo considerada a 6ª maior companhia de TI do planeta. Vale à pena lembrar que na década de 70 a IBM era disparada a maior companhia de TI do planeta.
Em 2008 a Oracle firma uma parceria com a HP e lança o Exadata, integrando o hardware e software num único produto com alta performance e inovações na relação entre storage e banco de dados. Em 2010 a Oracle compra a Sun e passa a desenvolver o Exadata sozinha, em a HP. Em 2013 a Oracle cria sua própria nuvem, porém ainda se encontra muito atrás dos seus principais compedidores: Amazon, Azure e Google.
Até breve…
Na parte II iremos explorar um pouco dos anos 80 e 90, onde vamos comentar o padrão SQL, o surgimento do Teradata, dBase, Sybase, MS SQL Server, Postgres, MySQL, testes TPC e até sobre bancos de dados orientados a objeto.
OBS: Para quem não sabe, a imagem no início do texto, é da unidade de discos do IBM RAMAC 350.
Removendo registros idênticos no PostgreSQL
23 de Outubro de 2017, 17:45 - sem comentários aindaEu sei, em teoria toda tabela deveria ter uma chave primaria e registros jamais poderiam ser duplicados. Mas a vida é uma caixinha de surpresas…. em algumas situações bem peculiares, você pode precisar de uma tabela sem uma PK, como numa área intermediária para a carga de dados. Estes dias a pergunta aparecer na lista do PGBR e eu resolvi mostrar aqui a solução:
postgres=# create table teste (t integer); CREATE TABLE postgres=# INSERT INTO teste VALUES (1), (2), (2), (3), (4); INSERT 0 5 postgres=# SELECT * FROM teste; t --- 1 2 2 3 4 (5 rows)
Note que os registros de número ‘2’ são idênticos e não temos como diferecia-los olhando apenas para os dados. A única diferença entre eles é o local onde estão armazenados no disco. E o campo que informa onde eles estão fisicamente armazenados se chama CTID, e ele tem um tipo de dados peculiar que é o TID. Um TID é um par de valores que representam o bloco onde e a posição do bloco onde o registro se encontra:
postgres=# SELECT ctid, * FROM teste; ctid | t -------+--- (0,1) | 1 (0,2) | 2 (0,3) | 2 (0,4) | 3 (0,5) | 4 (5 rows) postgres=# DELETE FROM teste WHERE ctid = '(0,2)'::tid; DELETE 1 postgres=# SELECT * FROM teste; t --- 1 2 3
PGConf Brasil 2017
27 de Junho de 2017, 18:32 - sem comentários aindaDe 10 a 14 de julho de 2017 vai rolar o primeiro PGConf.Brasil. Um evento focado em PostgreSQL, com 5 palestras, uma por dia, com temas extremamente relevantes para a área.
Inscreva-se para ter acesso aos 5 dias de palestras incríveis online: https://goo.gl/forms/GG0lS8v3403Z8iTI2
PALESTRANTES:
- 10/07: Flavio Gurgel com “Como detectar e corrigir índices corrompidos“
- 11/07: Bruce Momjian com “Postgres Window Magic“
- 12/07: Euler Taveira com “Replicação Lógica no PostgreSQL 10“
- 13/07: Matheus Oliveira com “PostgreSQL no mundo de micro-serviços, a experiência do iFood“
- 14/07: Álvaro Hernández com “Migrating off of MongoDB to PostgreSQL“
Postgres News
8 de Junho de 2017, 11:00 - sem comentários ainda2017 está sendo um ano de grande destaque bombar na comunidade PostgreSQL em todo o planeta e no Brasil não é diferente. Vamos às notícias:
- Em janeiro de 2017, o PostgreSQL é eleito em 3º lugar nos destaques do DB-Engines como “Database of The Year“. O PostgreSQL se mantém em 4º no ranking como o banco de dados relacional com uma forte e estável curva de crescimento no ranking.
- Depois de ir ao PGConf.Ru em 2016, parece que não consigo mais ver os eventos de PostgreSQL do mesmo jeito. O PGBR foi citado em 2011 como o maior evento de PostgreSQL do planeta, mas agora as coisas chegaram num novo patamar. Não somos mais um bando de nerds aficcionados por tecnologia, o universo se expandiu. Temos empresas de gente grande e eventos enormes rolando em todo o planeta, acompanhe alguns na página de eventos em https://wiki.postgresql.org/wiki/Events.
- Este ano será lançada a versão 10 do PostgreSQL com novas e aguardadas funcionalidades como O particionamento declarativo e a replicação lógica. Acompanhe as novidades no “Programa de Índio” especial sobre o assunto no canal da Timbira, que vai ao ar no dia 14/06.
- De 10 a 14 de Julho teremos o PGConf.Brasil com 5 palestras On-Line. O evento organizado pela Timbira é gratuito, só se inscrever no site.
- Dias 14, 15 e 16 de Setembro teremos a sétima edição do PGBR, o maior evento de PostgreSQL do Brasil, em Porto Alegre. As inscrições e a chamada de trabalhos estão abertas!
- Novos forks do PostgreSQL surgiram, além da versão famosa do EnterpriseDB, temos também versões próprias do postgres da Postgres Professional e da 2ndQuadrant. Olhando estas versões comercias você pode ver algumas funcionalidades que em breve deverão estar no core do PostgreSQL;
- Acha ainda que os forks são um problema? Então saiba que os forks tem esse hábito de voltar para a nave mãe:
- A Citus Data transformou o CitusDB em uma extensão livre do PostgreSQL;
- O Bizgres, criado pela Greenplum em 2005, comprado pela EMC em 2010 agora é Pivotal Greenplum baseado no Greenplum Database, 100% open source.
- A saga do projeto Postgres-XC que começou na NTT em 2010 parece que enfim está tendo um final feliz com o Postgres-XL com a 2ndQuadrant. Sim, o projeto ganhou fôlego e parece maduro finalmente.
- Um projeto que eu vira e mexe fico de olho é o PG-Strom, e se você se interessa por Big Data deveria acompanhar de perto também. Agora, além de utilizar GPU a partir de Foreign Data Wrapper, o projeto conta com complementos interessantes como o PL/GPU e o SSD-to-GPU. Não espere, vai lá e olhe de perto o que o Sr. KaiGai Kohei anda aprontando nas suas horas vagas lá na NEC.
- É claro que com tudo isso, a Timbira também cresceu! Como reflexo disso gostaria de destacar:
- A Timbira inaugurou seu canal no Youtube, com palestras, debates, tutoriais e outros vídeos relacionados ao bancos de dados. Acompanhe o canal e fique atento!
- Para quem não percebeu, a Timbira está com uma nova identidade visual, e uma presença mais marcante na Internet, com novo site, página no Twtter, Facebook, Instagram, etc.
- Além do material on-line, o nosso material físico mudou também: cartões de visita, chaveiros, banner, folder, adesivos e novas ideias que ainda vem por aí. Vejam as fotos do stand da Timbira no DBA Brasil 2.0!
Enfim, muito trabalho pela frente e muito o que comemorar também. Parece que o PostgreSQL está ganhando o reconhecimento que realmente merece no mercado. O resultado é visível em todos os lugares onde vamos. Mérito de todos que acreditaram e contribuem todos os dias para o banco de dados livre mais avançado do mundo!

{kind=link}