


O PSL-PI tem por objetivo incentivar o uso e a produção de software livre no Piauí como política de combate à exclusão digital. Acreditamos que a distribuição de conhecimentos proporcionada pelo Open Source/Software Livre tornará nossa sociedade mais justa e próspera, exatamente por dar a todos as mesmas condições de conhecimento e desenvolvimento.
Software Livre é uma grande oportunidade de construirmos uma sociedade produtora de ciência, independente e efetivamente competitiva. Estamos reconstruindo as bases da nossa sociedade, não mais calcados nos braços do Estado, mas sim, amparados pela iniciativa própria, pela auto-determinação. Nós somos capazes de nos auto-governar. Somos capazes de construir uma sociedade efetivamente Livre. Esta é a essência do PSL-PI.
O PSL-PI é formado pela articulação de indivíduos que atuam em instituições publicas e privadas, grupos de usuários e desenvolvedores de software livre, empresas, governos ou ONGs, e demais setores da sociedade. O importante é a consciência e disposição para propagar o uso de software livre e a cultura colaborativa nas diferentes esferas da sociedade.
Regis Pires: Entrevista de Celso Vasconcelos sobre Avaliação da Aprendizagem
4 de Junho de 2011, 0:00 - sem comentários aindaExcelente entrevista do Prof. Celso Vasconcelos sobre Avaliação de Aprendizagem:http://www.educacaoetecnologia.org.br/?p=4919







Regis Pires: Fuseki: um servidor SPARQL simples
3 de Junho de 2011, 0:00 - 2 comentáriosO pessoal do projeto Jena lançou em janeiro de 2011 o Fuseki. Ele é um servidor SPARQL 1.1 focado na simplicidade de uso, algo que eu realmente adoro e valorizo!!!
O Joseki foi usado inicialmente em um Workshop sobre Linked Data segundo Andy Seaborne, um dos seus desenvolvedores:
“it’s been trailed at a workshop for people new to linked data”.Suporta o protocolo SPARQL HTTP, a linguagem SPARQL Query e a linguagem SPARQL Update.
O objetivo dele é permitir a publicação, o gerenciamento e o consumo de dados RDF de forma simples.
O arquivo jar dele (fuseki-sys.jar) já tem embutidas as seguintes ferramentas: Jena, ARQ (SPARQL query engine) e TDB (RDF Store).
Ao inicializarmos o servidor, temos uma interface Web capaz de realizar consultas, atualizações e upload de arquivos rdf diretamente para o dataset usado.
As consultas podem ser federadas, ou seja, acessar mais de uma fonte de dados através do uso da operação SERVICE. Também permite o uso de vários grafos RDF que podem ser configurados para serem acessados como se fizessem parte do grafo default.
Algumas limitações que serão tratadas em futuras versões são:
- Cada instância do servidor Fuseki somente gerencia um único dataset.
- Ainda não há como definir restrições de segurança.
- Não permite o armazenamento em banco relacional através do SDB, mas somente em memória (in-memory) ou em RDF Store (TDB).
Espero que o Fuseki possa evoluir rápido. Ele faz muita coisa que o Joseki fazia de forma muito mais simples, mas ainda com algumas limitações.
Falando sobre isso, o desenvolvedor Andy Seaborne diz: “Think of Fuseki as ‘Joseki 4′. It’s a chance to simply and tidy up.”.
Ou seja, é como se fosse um Joseki mais simples e arrumado.
Para saber mais sobre o Fuseki e sobre o projeto Jena, veja estes slides.







Regis Pires: 20 lições que aprendi sobre navegadores e a web
3 de Junho de 2011, 0:00 - sem comentários aindaUm guia divertido do Google sobre navegadores e a web para pessoas que usam a internet mas não são técnicas:
http://www.20thingsilearned.com/pt-BR







Filipe Saraiva: Scilab says: “Hello Cantor!”
3 de Junho de 2011, 0:00 - 3 comentários…and also makes calculations!
In recent weeks, I worked primarily with the communication between Cantor and Scilab, via the backend that I am developing. The task was very interesting because in the project, the technology chosen for implementation, was changed.
Before, I had proposed to use the API call_scilab, which makes the communication between the C/C++ and Scilab. But, studying the code of Cantor, I realized that other backends uses KProcess class (or QProcess), which allows Qt code to initialize a thread of other software and make communication with him via the standard streams stdout, stderr and stdin.
However, Scilab originally did not use these streams. So, talking to my mentor Ledru, we decided to implement this functionality.
After a few days and further studies, could provide support to these outputs in Scilab! And, voilá, Scilab says “Hello Cantor!” via backend! Click images to enlarge:
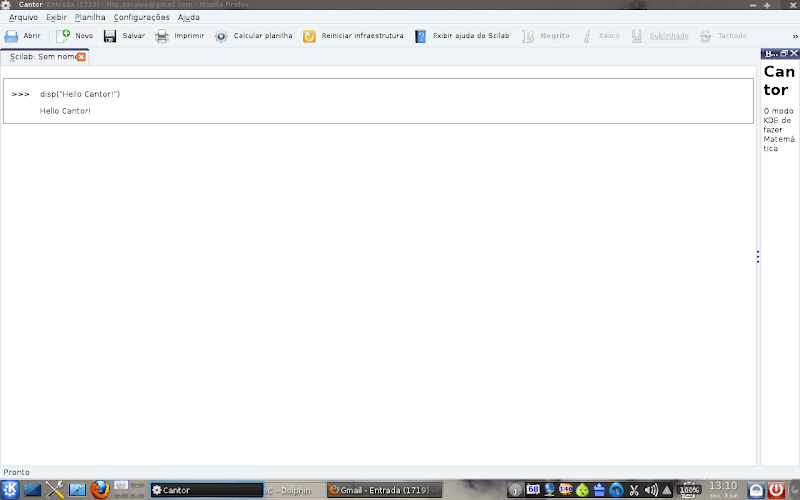
The backend is actually functional, although, of course, missing a few details. Now we have many screenshots. ![]()
Backend for Cantor Scilab making calculations:
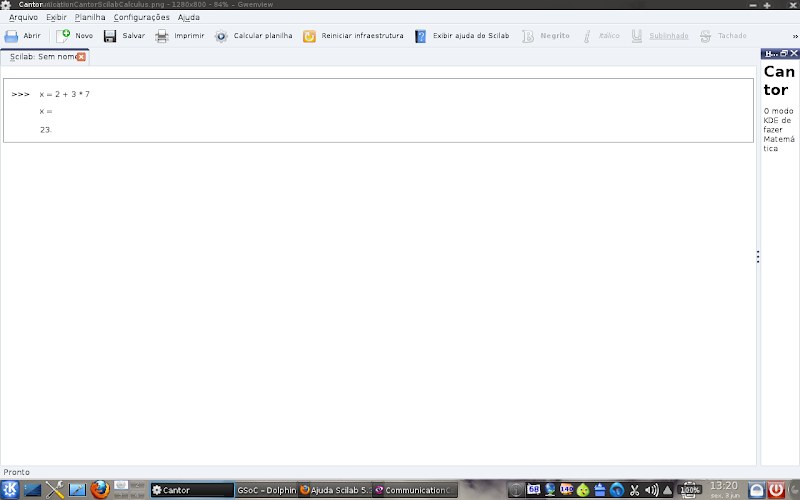
Add variables, uses pre-defined functions and allows various calculations in the same workspace:
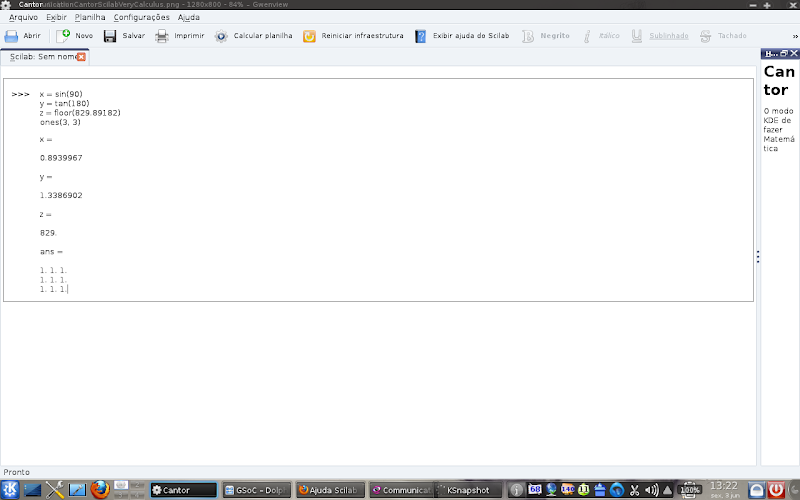
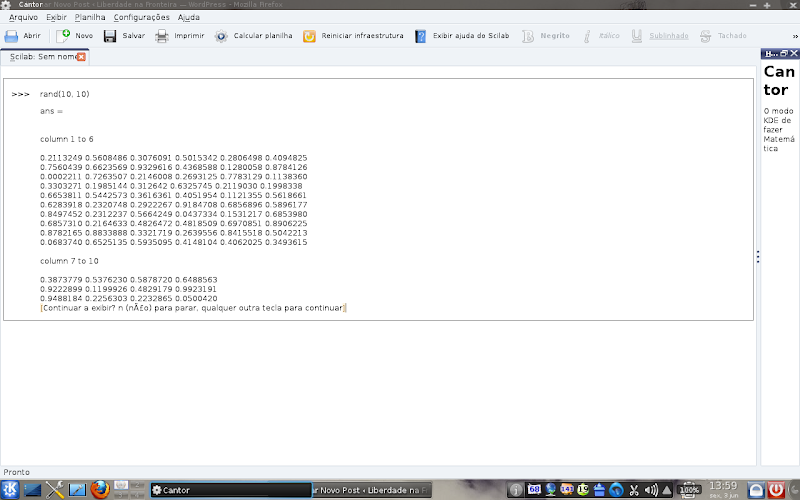
Works with multiple workspaces simultaneously:
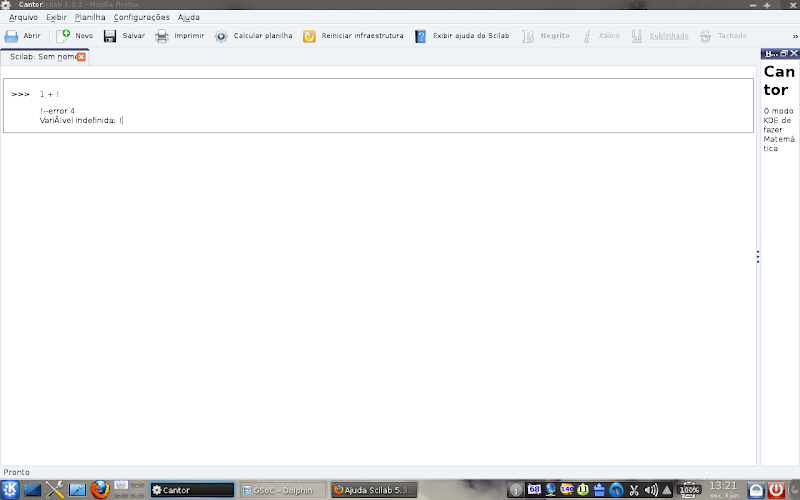
Emits error messages in the workspace:
That’s it! Well, let’s now a great resume with quick information about this project:
What’s missing?
- Management charting. Nowadays, the backend generates the chart of Scilab in another window. This will add the possibility of generating the chart in the workspace of the Cantor;
- Syntax highlighting;
- Auto-complete of the native Scilab functions;
- Working the character encoding of the output;
- Manage large outputs. When Scilab is a calculation and will print stuff on screen, the environment shows only a portion of the output and asks if the user wants to see more. In the backend it does not work, because when the first part of the output is shown, it is impossible to send another entry to Scilab. Below, in the image:
I can test this backend?
The backend code is in the branch scilab-backend Cantor repository, and performs all the functions described here. However, it needs the Scilab repository version to work, because I had to implement support for streams standards – ie, you must download the Scilab code and compile it. Another time, I’ll write a post with some tips on compiling Scilab.
For those who do not want to venture into the process of compiling Scilab, the way is to wait for the next version of Scilab to be launched in September. Just as it does in Scilab backend for Cantor function.
So that’s friends, who have to read the text here and stay tuned for more news. And do not forget to comment here about what you’re thinking of this project. ![]()
Filipe Saraiva: Scilab diz: “Hello Cantor!”
3 de Junho de 2011, 0:00 - sem comentários ainda…e também faz cálculos!
Nestas últimas semanas, trabalhei basicamente com a comunicação entre o Cantor e o Scilab, via o backend que estou desenvolvendo. A tarefa foi bem interessante pois houve mudanças no projeto, na tecnologia escolhida para a implementação.
Antes eu havia proposto o uso da API call_scilab, que faz a comunicação entre código C/C++ com o Scilab. Mas, estudando o código do Cantor, percebi que os demais backends utilizam a classe KProcess (ou QProcess), que permite que código em Qt inicialize uma thread de outro software e faça a comunicação com ele via os streams padrões stdout, stderr e stdin.
Entretanto, o Scilab originalmente não usava esses streams. Então, conversando com meu mentor Ledru, resolvemos implementar essa funcionalidade.
Após alguns dias e mais estudos, consegui prover o suporte a estas saídas no Scilab! E, voilá, Scilab diz “Hello Cantor!” via backend! Clique nas imagens para ampliar:
O backend está de fato funcional, apesar de, claro, faltarem alguns detalhes. Agora teremos muitas screenshots. ![]()
Backend do Cantor para o Scilab faz cálculos:
Adiciona variáveis, usa funções pré-definidas e permite vários cálculos em um mesmo workspace:
Trabalha com vários workspaces simultaneamente:
Emite as mensagens de erro no workspace:
É isso! Bem, vamos agora a um resumão com informações rápidas sobre este projeto:
O que falta?
- Gerenciamento de criação de gráficos. Atualmente, o backend gera o gráfico do Scilab em outra janela. Será adicionada a possibilidade de geração do gráfico dentro do workspace do Cantor;
- Destaque de sintaxe;
- Alto-complete de funções nativas do Scilab;
- Trabalhar a codificação dos caracteres da saída;
- Gerenciar saídas grandes. Quando Scilab faz um cálculo e vai imprimir muitas informações na tela, o ambiente mostra apenas uma parte da saída e pergunta se o usuário quer ver mais. No backend isto não funciona, pois quando a primeira parte da saída é mostrada, não há mais como enviar outra entrada para o Scilab. Veja abaixo, na imagem:
É possível testar este backend?
O código do backend que está no branch scilab-backend do repositório do Cantor realiza todas as funções aqui descritas. Entretanto, ela precisa da nova versão do Scilab para funcionar, pois tive que implementar o suporte aos streams padrões – ou seja, é necessário baixar o código do Scilab e compilá-lo. Em outro momento, irei escrever um post com algumas dicas sobre a compilação do Scilab.
Para quem não quer se aventurar no processo de compilação do Scilab, o jeito é esperar a próxima versão do Scilab que deve ser lançada em setembro. Apenas a partir dela é que o backend para Scilab no Cantor funcionará.
Então é isso amigos, obrigados a aqueles que leram o texto até aqui e fiquem atentos para maiores novidades. E não deixe de fazer um comentário aqui sobre o que você está achando desse projeto. ![]()
