




Tribunal Regional do Trabalho: Implantação Bacula Enterprise
7 de Outubro de 2020, 2:30 - sem comentários aindaIniciada no segundo semestre de 2020, a implantação do Bacula Enterprise Edition no Tribunal Regional do Trabalho (TRT) de Minas Gerais foi um sucesso. Em agosto foi realizado o treinamento in company, com repasse tecnológico, para a equipe de tecnologia do TRT.
Trata-se de uma migração do antigo IBM TSM para a nova solução de backup e restauração de dados – Bacula Enterprise. O mesmo protege agora o PJe e demais sistemas críticos do TRT3. Foram utilizados diversos plugins do Bacula para backup das bases de dados PostgreSQL e OracleDB, com paralelismo, deduplicação global em nível de blocos e outras do estado da arte em backups. Também foi utilizada replicação de Jobs do bacula para redundância geográfica. O backup de clusters de máquinas virtuais VMware VSphere também é utilizado.
Além das questões legais pertinentes aos bons princípios da administração pública que envolvem a adoção do Bacula por órgãos públicos, existem também diversas questões técnicas fundamentais oferecidas pelo Bacula:
- 30 anos de retrocompatibilidade de backups
- Formato aberto do catálogo de gravação: o Bacula gera o backup em formato aberto (não proprietário) de gravação (pode ser lido pelo tar e dump do Unix)
- Suporte ao backup de snapshots
- Compressão do tráfego de rede
- Sem cobranças por volume de dados backupeados
- Economia de espaço de armazenamento e uso de banda de rede com a tecnologia de Deduplicação Global (Global Endpoint Deduplication). A deduplicação é fundamental para as empresas que possuem diversas unidades descentralizadas (com filiais em diferentes prédios) por apresentar uma economia de até 99% no tráfego e no armazenamento de backup
- Gravação dos dados backupeados em formato aberto (não proprietário) permitindo que a organização usuária não seja vítima de aprovisionamento tecnológico
- Armazenamento do seu catálogo em banco de dados padrão SQL, como PostgreSQL, MySQL e Oracle
- Capacidade de armazenamento variável: de 10 GigaByte até 1 PetaByte
- Descentralização de tarefas de backup e recuperação de dados com a interface BaaS
- Controle de acesso para gerenciamento via Active Directory (LDAP)
- Rápida recuperação de desastres.
Quer planejar a migração do Centro de Dados da sua organização com ganho de gestão e redução de custos? A licença do Bacula já inclui o BWeb (interface gráfica exclusiva) e o plugin de Deduplicação Global Endpoint. No caso do TRT3 também foram utilizados os plugins VSphere, Oracle DB, PGSQL, SQL Server, Bare Metal Linux e Windows, AWS S3, RHV, Docker.
O Bacula Enterprise tem o maior catálogo de plugins do mercado, ou seja, soluções para todos os data centers!
Entre em contato com a equipe Bacula!
bsplitter – Divisão Dinâmica de FileSets do Bacula para Backups paralelos
21 de Setembro de 2020, 0:29 - sem comentários aindaEste script permite listar dinamicamente subdiretórios e arquivos de um diretório de backup, divindo listas de arquivos para backup classificadas por tamanho.
No exemplo do comando:
/opt/bacula/scripts/bsplitter 3 1 /var/lib/pgsql
- “3” é o número total de Jobs e FileSets. Estes precisam ser criados manualmente pelo administrador, e devem ser configurados para execução em paralelo.
- “1” é a parcela do backup que será realizado. Então para cada FileSet, você modificará a parcela que será backupeada. Exemplo:
FileSet1: bsplitter 3 1 /var/lib/pgsql
FileSet2: bsplitter 3 2 /var/lib/pgsql
FileSet3: bsplitter 3 3 /var/lib/pgsql
- “/var/lib/pgsql” é o diretório cujo conteúdo do backup será fracionado em parcelas.
Se estiver usando BWeb, como na Figura 1, basta chamar o script a seguir no campo Include do FileSet:
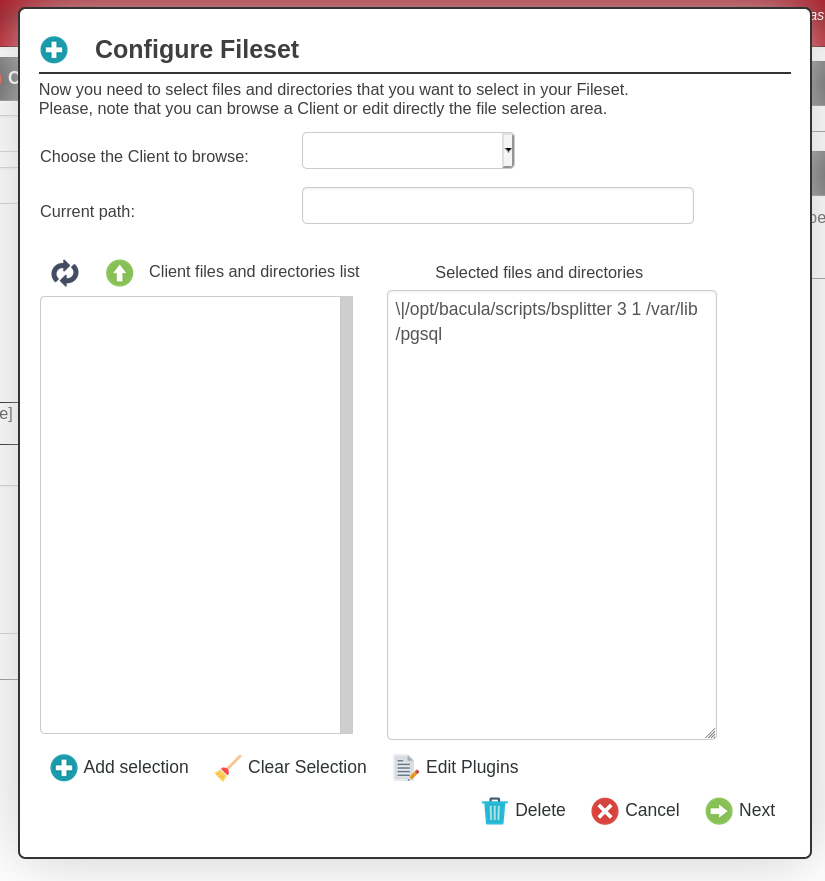 Figura 1. No BWeb, basta inserir no Include: \|/opt/bacula/scripts/bsplitter 3 1 /var/lib/pgsql
Figura 1. No BWeb, basta inserir no Include: \|/opt/bacula/scripts/bsplitter 3 1 /var/lib/pgsql
Segue o script, a ser salvo idealmente no caminho “/opt/bacula/scripts/bsplitter” de seu host Cliente do backup.
#!/bin/bash
#
# Autoria: Heitor Faria (Copyleft: all rights reversed).
# Orientador: Prof. Julio Neves (http://www.livrate.com.br/).
# Testador: xxxx
#
# Deve ser chamado no sub-recurso INCLUDE do FileSet do bacula-dir.conf, referente ao backup do cliente instalado que deseja fracionar a quantidade de subdiretórios:
#
# File = "\\|/opt/bacula/scripts/bsplitter 3 1 /var/lib/pgsql"
# <parallelism><parcel><dir_to_split>
#
#
bwdir="/opt/bacula/working"
sname=$(sed 's|/|.|g' <<< $3)
# tempo mínimo entre a verificação de novos arquivos, em minutos. 22 horas padrão
minupdate=1320
if [ $(find $bwdir/$sname.txt -mmin -$minupdate 2>/dev/null | wc -l) -eq 0 ]
then
rm -f $bwdir/$sname.part*
ListaOrdenada=$(find $3 -type f -printf "%s\t%p\n" | sort -nr | cut -f2 | sed 's/ /^/') # subst o espaço por ^ para não quebrar
ApontaVet=o
Sinal=1
while read Arq
do
let ApontaVet+=Sinal
((ApontaVet > $1)) && {
let ApontaVet--
let Sinal*=-1
}
((ApontaVet < 1)) && {
ApontaVet=1
let Sinal*=-1
}
eval V$ApontaVet+='($Arq)'
done < <(echo "$ListaOrdenada")
for ((N=1; N<=$1; N++))
do
eval TodosArqs=\${V$N[@]} # Gera uma linha com todos arquivos para cada vetor
for Nome in $TodosArqs # Desmembra a lista um a um para criar a pilha de arquivos
do
eval Nome=\${Nome//^/ }
echo $Nome >> $bwdir/$sname.part$N
done
done
fi
cat $bwdir/$sname.part$2
Obs.: FileSets dinâmicos não são compatíveis com o Exclude do bacula. Exclusões devem ser tratadas no próprio script.
No exemplo específico do PostgreSQL, para garantia de integridade, este backup está sendo feito de um snapshot de LVM montado em outra máquina. De outra maneira o banco teria de ser parado durante o backup ou colocado em modo backup (ex.: com o plugin Bacula Enterprise pgsql).
De qualquer maneira, o bsplitter pode ser utilizado para qualquer conjunto grande de arquivos de um mesmo host, para o qual se deseja paralelismo.
Restore
Na restauração, você pode concatenar os n conjuntos de jobs feitos para uma única operação de restore, informando os jobids dos jobs paralelizados. Exemplo bconsole:
restore jobid=x,y,z
No BWeb, como exibido na Figura 2, também é possível concatenar diversos Jobs na tela de seleção de arquivos para restores, desmarcando a opção “Only Selected Fileset”
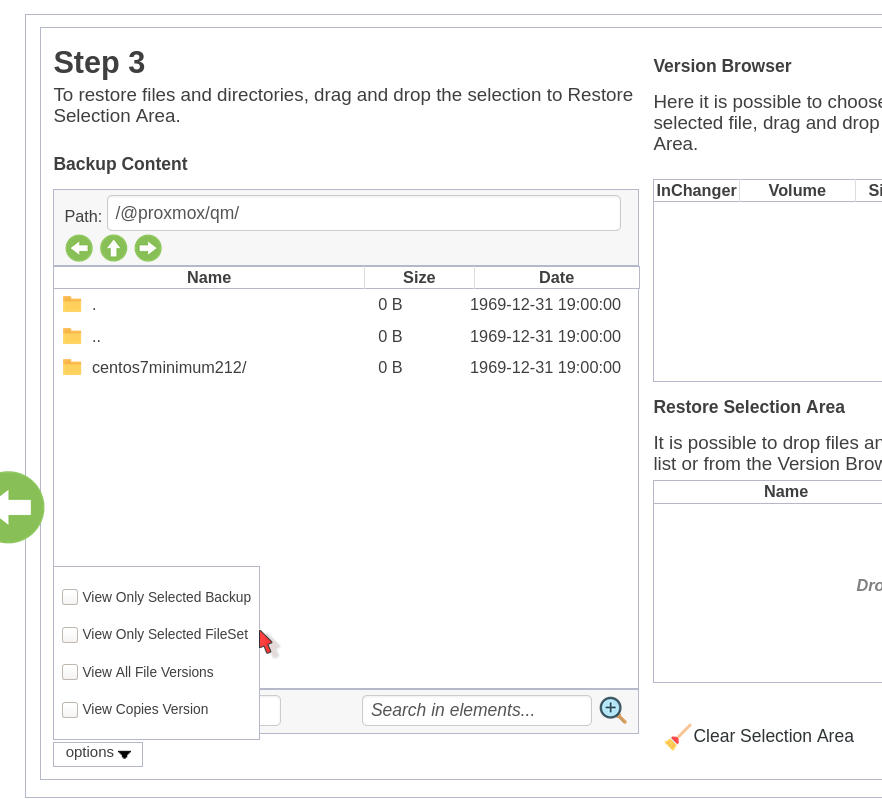 Figura 2. Restauração múltiplos Jobs BWeb, desmarcando “Only Selected Fileset”
Figura 2. Restauração múltiplos Jobs BWeb, desmarcando “Only Selected Fileset”
Backup de Volumes do CEPH com o plugin Bacula bpipe e RBD Export
17 de Setembro de 2020, 22:45 - sem comentários aindaJá vimos no passado como o bpipe possibilita o backup de inúmeras aplicações através de comandos para a saída padrão do Linux <http://www.bacula.lat/usando-o-bpipe-para-stream-de-dumps-clones-de-maquinas-virtuais-e-outros-dados-para-seu-backup/>.
rbd é um utilitário para manipular imagens de dispositivos de bloco rados (RBD), usado pelo driver Linux rbd e pelo driver de armazenamento rbd para QEMU/KVM. As imagens RBD são dispositivos de bloco simples que são distribuídos em objetos e armazenados em um armazenamento de objeto RADOS. O tamanho dos objetos sobre os quais a imagem é listrada deve ser uma potência de dois.
O shell script abaixo pode ser instalado no cliente do Bacula com acesso ao cliente RBD, para listagem dos volumes de uma Pool do CEPH, snapshot e export do snapshot. Backups diferenciais e incrementais são suportados.
#!/bin/bash
#
# Autoria: Heitor Faria (Copyleft: all rights reversed).
# Testado por: xxxx
E
# Deve ser chamado no sub-recurso INCLUDE do FileSet do bacula-dir.conf, referente ao backup do cliente instalado na máquina do CEPH (por exemplo), por Pool do CEPH:
#
# Plugin = "\\|/opt/bacula/scripts/bpipe_rbd %l <pool_ceph>"
# $1 $2
#
time=$(date +%F_%H-%M-%S)
if [[ $1 == 'Incremental|Differential' ]]
then
exp="export-diff"
imp="import-diff"
fi
if [[ $1 == Full ]]
then
exp="export"
imp="import"
fi
for vol in $(rbd -p $2 ls); do
rbd snap create --pool $2 --image $vol --snap $vol-$time
echo "bpipe:/var/$vol:rbd $exp --pool $2 --image $vol --snap $vol-$time --path -:rbd $imp --dest-pool $2 --dest $vol --path -"
done
Para fazer a restauração, o volume original do CEPH precisa ser renomeado ou apagado.
De igual sorte, o comando definido de restauração (rdb import) pode ser substituído posteriormente no momento do restore do Bacula para gravação do volume em disco. Exemplo: dd of=/tmp/nome_volume
Tuning: Melhor Performance e Tratamento de Gargalos do Backup
1 de Setembro de 2020, 3:00 - sem comentários aindaBacula
- Algumas empresas usam Antivírus para Windows e até para Linux. Coloque os Daemons do Bacula como excessões de verificação.
- Dividir o FileSet em dois quando for fazer backup de mais de 20 milhões de arquivos.
Especialmente os sistemas de arquivos do Windows não lidam bem com volumes com quantidade gigantesca de arquivos pequenos. Neste caso, o ideal é criar múltiplos FileSets e Jobs (ex.: um para cada Volume ou alguns diretórios), de maneira a paralelizar as operações de cópia. Por exemplo, um servidor com volumes C: e E:.
Job1, FileSet1. Include, File = “C:/”
Job2, FileSet2. Include, Plugin = “alldrives: exclude=C”
Job3, FileSet3. Include, Plugin = “vss:/@SYSTEMSTATE/”
O uso do alldrives é importante para fazer backup de todos os outros drives exceto o C:, que já é backupeado pelo Job1. Se alguém criar um novo Volume neste servidor, o Job2 já irá fazer backup automaticamente.
O Job3 seria para backup exclusivo do System State do Windows (caso deseje separar também). O vss: é um plugin exclusivo do Enterprise, mas também é possível utilizar scripts para gerar o System State do Windows em um volume aparte.
Em algumas interfaces gráficas (como a Bweb), é possível agrupar os Jobs de um mesmo cliente para fins de melhor gestão e estatísticas.
- Diminuir o nível de compressão do GZIP (se habilitado – sempre menos de 6) ou utilizar LZO. Não usar a compressão via software do Bacula para fitas.
- Executar múltiplos jobs de backup simultâneos (Maximum Concurrent Jobs).
Tenha certeza de habilitar a concorrência nos 4 lugares:
a) Recurso Director no bacula-dir.conf
b) Recurso Storage no bacula-dir.conf
c) Recurso Storage no bacula-sd.conf
d) Recurso Device stanza in bacula-sd.conf
- Fazer backup em múltiplos discos, fitas ou diferentes storages daemons simultâneamente.
- Fitas: Habilitar o Spooling de Disco SSD/NVME. Discos HD tradicionais podem ser mais lentos que as fitas.
- Fitas: Aumentar o Minimum (ex.: 256K) e Maximum Block Size para 256K a 512K (*para LTO4. 1M muito grande e pode gerar problemas. Especificado no: bacula-sd.conf, recurso Device). Necessário recriar todos os volumes com o novo tamanho máximo de bloco, caso contrário o Bacula não conseguirá ler os anteriores.
- Fitas: Aumentar o Maximum File Size para 10GB to 20GB (Especificado no: bacula-sd.conf, recurso Device).
- Desabilitar o AutoPrunning de Clientes e Jobs (Prunar os volumes uma vez por dia através de um Admin Job).
- Turn on Attribute Spooling for all Jobs (Padrão para a versão 7.0 em diante).
- Utilizar inserção em lotes (batch insert) no banco de dados (normalmente é padrão, definido na compilação e precisa ser suportado pelo banco).
Catálogo (banco de dados)
a) PostgreSQL
- Evitar a criação de índices acicionais.
- Utilizar configurações especiais para o Postgresql (postgresql.conf):
wal_buffers = 64kB
shared_buffers = 1GB # up to 8GB
work_mem = 64MB
effective_cache_size = 2GB
checkpoint_segments = 64
checkpoint_timeout = 20min
checkpoint_completion_target = 0.9
maintenance_work_mem = 256MBsynchronous_commit = on
- Realização (periódica) de um vacuumdb na base de dados (postgreSQL), com o passar do tempo a grande alteração de registros acaba por deixar a inserção no banco mais demorada. [1]
[1] Dica do Edmar Araújo. Referências: http://www.postgresql.org/docs/9.0/static/app-vacuumdb.html | Carlos Eduardo Smanioto -> Otimização – Uma Ferramenta Chamada Vacuum: http://www.devmedia.com.br/otimizacao-uma-ferramenta-chamada-vacuum/1710
b) MySQL
- Utilizar configurações especiais para o MySQL:
sort_buffer_size = 2MB
innodb_buffer_pool_size = 128MBinnodb_flush_log_at_trx_commit = 0
innodb_flush_method = O_DIRECT
Como padrão, o innodb_flush_log_at_trx_commit seria 1, significando que o log da transação é armezenado no disco a cada commit no banco e as transações não seriam perdidas no caso de um crash do sistema operacional. Como o Bacula utiliza muitas transações pequenas, você pode reduzir o I/O das logs e aumentar exponencialmente a performance dos backups configurando para 0, significando que não haverá armazenamento de log a cada transação. Como caso de interrupção seria necessário reiniciar o job de backup de qualquer sorte, mostra-se uma opção bastante interessante.
- Executar o mysqltuner (apt-get install mysql tuner) e implementar as modificações sugeridas.
Rede (SD e FD)
- Adicionar mais interfaces (bonding/NIC Teaming) e switches mais rápidos (pode usar o comando do Bacula status network ou a aplicação ethtool para verificar a velocidade de sua conexão ethernet).
- Ajustar o Maximum Network Buffer Size = bytes, que especifica o tamanho inicial do buffer de rede. Este tamanho é ajustado para baixo se o SO operacional não aceitar, ao custo de muitas chamadas de sistemas (não desejado). O valor padrão é 32,768 bytes. O padrão foi escolhido para ser largo o suficiente para transmissão via internet, mas em uma rede local pode ser aumentado para melhoria da performance. Alguns usuários perceberam uma melhoria de 10 vezes de transferência de tados utilizando 65,536 bytes neste valor.
- Evitar tráfego por firewalls e roteadores.
- Usar Frames Jumbo.
- Customizar o Kernel (Ref.: https://fasterdata.es.net/host-tuning/linux/. Exemplo:
echo " # allow testing with buffers up to 128MB net.core.rmem_max = 134217728 net.core.wmem_max = 134217728 # increase Linux autotuning TCP buffer limit to 64MB net.ipv4.tcp_rmem = 4096 87380 67108864 net.ipv4.tcp_wmem = 4096 65536 67108864 # recommended default congestion control is htcp net.ipv4.tcp_congestion_control=htcp # recommended for hosts with jumbo frames enabled # net.ipv4.tcp_mtu_probing=1 # recommended for CentOS7+/Debian8+ hosts net.core.default_qdisc = fq" >> /etc/sysctl.conf reboot
Sistema Operacional
- RAM (> 8GB)
- vm.dirty_ratio = 2
- vm.dirty_background_ratio = 1
- vm.swappiness = 10
- vm.zone_reclaim_node = 0
Acesso aos Discos
- Use o sistema de arquivos XFS, pois ele se destaca na execução de operações paralelas de entrada/saída (E/S) devido ao seu design, que é baseado em grupos de alocação (um tipo de subdivisão dos volumes físicos nos quais o XFS é usado, encurtado para AGs). Por causa disso, o XFS permite extrema escalabilidade de threads de E/S, largura de banda do sistema de arquivos e tamanho dos arquivos e do sistema de arquivos em si, ao abranger vários dispositivos de armazenamento físico.
- Usar o “deadline disk scheduler”.
- Usar RAID com um bom controlador com bateria (ex.: ARECA).
Treinamento Bacula na Marinha do Brasil
1 de Setembro de 2020, 1:38 - sem comentários aindaOs Treinamentos in Companny oferecidos pela Bacula Brasil e América Latina podem chegar com facilidade a qualquer organização preocupada com a qualificação de seus profissionais e aprimoramento na gestão dos Centros de Dados. Este mês ocorreu a formação Bacula Communty online para os profissionais de tecnologia do Centro de Hidrografia da Marinha.
Quer saber mais sobre os Treinamentos Bacula In Company?
Nossa Agenda de Treinamentos é flexível! Entre em contato para consultar disponibilidade de data.
- Bacula Community e Enterprise: oferecemos Treinamento In Company para todas as versões do Bacula incluindo as suas soluções e plugins.
- Repasse tecnológico: a Bacula trabalha para libertar os centros de dados do aprisionamento tecnológico. Por isso acreditamos na importância de compartilhar nosso conhecimento especializado além de reduzir direta e significativamente os custos de backup e restauração dos data centers. Conheça a Nossa Missão
- Certificado: concedido ao final do curso (em formato digital) aos alunos com frequência superior a 75% (setenta e cinco por cento).
- Ementa: flexível de acordo com as necessidades da organização.
- Prática e teoria: implementando uma estrutura corporativa de backup durante a realização do treinamento.
- Material: todos recebem a versão mais recente do livro do Bacula e acesso vitalício ao conteúdo online do Bacula na plataforma Udemy.
- Instrutor: Heitor Medrado de Faria é autor de livro Best Seller sobre o Bacula (único livro nacionaldedicado à parte teórica de backups) e possui Público e Notório saber sobre os assuntos abordados. Fundador da comunidade brasileira de usuários do Bacula foi palestrante em diversos eventos nacionais e ministrou mais de 100 cursos sobre a ferramenta nos últimos 10 anos, inclusive para diversos órgãos do governo. Também é pós-graduado em gestão de Serviços de TI e Certificado LPIC nível 3.
Acesse os atestados de Capacidade Técnica
Veja nossos Cases
Atenção!
Órgãos e empresas públicas: o valor de investimentos no treinamento atende às regras de Inexigibilidade de Licitação, com valor total de até R$ 16.900,00 e todos os custos inclusos.
Como variante à contratação do Treinamento Bacula In Company pode ser adicionado o melhor Suporte Anual Remoto para seu sistema de backups.
Estamos aguardando seu contato! Entre em contato com a nossa equipe e saiba mais.
